
An Educational Chat With Grok
The other day I was conversing online with another system engineer who brought up the issue of emergent behavior as a defined characteristic of a system. I found this unusual, as the intent of system engineering and overall good engineering practice would be to avoid emergent behavior completely. Unfortunately we were having difficulty establishing a common vocabulary, so I decided to ask an AI assistant. In this case, I used Elon Musk’s Grok, which I have come to like. If I had researched this on my own, it would have taken days to research, and longer to write an article about it. Engineers can read the chat I conducted with Grok below; I hope you find it useful.
Note that I used a conversational style, which made bringing this article together much easier. I think it took more time to assemble and format this article than to have the chat.
Let’s start simple to make sure we’re on the same page…
VMCSE: What is the definition of a system?
Grok: A system is a set of interconnected components that work together to achieve a common purpose or function. These components can be physical, biological, social, or abstract, and they interact within a defined boundary, often influenced by inputs and producing outputs. Systems can range from simple (e.g., a mechanical device) to complex (e.g., an ecosystem or organization), and they often exhibit properties like feedback, adaptation, or emergence that arise from the interactions of their parts. (emphasis mine)
(Note: This chat occurred in two sessions at different times. You’ll see me ask the next question again later.)
VMCSE: What is the meaning of emergence in this context?
Grok: In the context of systems, emergence refers to the phenomenon where complex behaviors, properties, or patterns arise from the interactions of relatively simple components within the system, which could not be predicted or fully explained by analyzing the individual parts alone. These emergent properties are often novel and unique to the system as a whole.
For example:
• In a biological system like an ant colony, individual ants follow simple rules, but their collective interactions lead to complex behaviors like efficient foraging or nest-building, which are emergent properties of the colony.
• In a social system, the culture or economy of a society emerges from the interactions of individuals, even though no single person fully controls or predicts the outcome.
Emergence highlights how the whole system can exhibit characteristics greater than or different from the sum of its parts.
VMCSE: What are tests to identify a system of systems as opposed to just a system?
Grok: A System of Systems (SoS) is a collection of independent, self-contained systems that interoperate to achieve a higher-level purpose, distinct from a single, unified system. Identifying an SoS versus a standalone system involves evaluating specific characteristics and applying tests based on established criteria. Below are key tests and criteria to differentiate an SoS from a single system, grounded in systems engineering principles:
Key Characteristics of a System of Systems
Based on literature, such as Maier (1998) and subsequent SoS frameworks, an SoS typically exhibits:
1. Operational Independence: Each constituent system can operate independently and fulfill its own purpose outside the SoS.
2. Managerial Independence: Constituent systems are managed and governed independently, often by different organizations or stakeholders.
3. Geographical Distribution: Systems are often physically or logically distributed, interacting across boundaries.
4. Emergent Behavior: The SoS produces outcomes or capabilities that emerge from the collaboration of systems, not achievable by any single system alone.
5. Evolutionary Development: The SoS evolves over time, with systems added, removed, or modified dynamically.
Tests to Identify a System of Systems
These tests assess whether a given entity qualifies as an SoS rather than a monolithic system:
1. Independence Test:
• Question: Can the constituent systems operate independently and still achieve their own objectives outside the context of the larger system?
• Method: Evaluate whether each subsystem (e.g., a satellite, a hospital, a software application) can function standalone without relying on the SoS. For example, in a smart city SoS, traffic management, power grid, and communication networks can operate independently.
• SoS Indicator: If subsystems maintain operational and managerial autonomy, it’s likely an SoS. In contrast, a single system (e.g., a car engine) has tightly coupled components that cannot function independently.
2. Interoperability Test:
• Question: Do the systems collaborate through defined interfaces or standards to achieve a collective goal?
• Method: Check for standardized protocols, data exchanges, or communication frameworks enabling interaction (e.g., APIs in software SoS, or military communication protocols in defense SoS). For instance, in an air traffic control SoS, radar, aircraft, and control towers interoperate via standardized aviation protocols.
• SoS Indicator: Loose coupling via interfaces, as opposed to tight integration in a single system (e.g., a single software application with internal modules).
3. Emergent Capability Test:
• Question: Does the collective system produce capabilities or behaviors that no individual system can achieve alone?
• Method: Identify outcomes unique to the SoS. For example, a disaster response SoS (comprising hospitals, emergency services, and communication networks) enables coordinated recovery, which no single system could accomplish.
• SoS Indicator: Presence of emergent properties (e.g., global internet functionality from networked systems) versus predictable outputs from a single system’s components.
4. Governance and Ownership Test:
• Question: Are the constituent systems managed or owned by different entities with potentially conflicting objectives?
• Method: Analyze the organizational structure. For example, a global supply chain SoS involves independent companies (manufacturers, logistics, retailers) with separate management. Contrast this with a single system like a factory, managed under one authority.
• SoS Indicator: Diverse governance and stakeholder conflicts suggest an SoS.
5. Evolutionary Dynamics Test:
• Question: Does the system evolve by adding, removing, or modifying constituent systems over time?
• Method: Examine whether the system is designed to accommodate changes dynamically. For example, the internet as an SoS evolves with new servers, protocols, or devices joining or leaving, unlike a single system like a spacecraft with fixed components.
• SoS Indicator: Dynamic reconfiguration and adaptability point to an SoS.
6. Geographical or Logical Distribution Test:
• Question: Are the constituent systems physically or logically dispersed, requiring coordination across boundaries?
• Method: Assess the spatial or operational distribution. For example, a military SoS (ships, aircraft, satellites) operates across vast distances, unlike a single system like a tank with co-located components.
• SoS Indicator: Significant distribution requiring networked coordination supports an SoS classification.
Practical Application
To apply these tests:
• Map the System: Identify the components, their interactions, and boundaries.
• Evaluate Against Criteria: Use the tests above systematically, documenting evidence for each characteristic.
• Compare to Single System: A single system typically has tightly coupled components, unified management, and a fixed structure, lacking the independence or emergent scale of an SoS.
Examples for Clarity
• SoS Example: The global air transportation system is an SoS. Airlines, airports, air traffic control, and weather systems are independent, interoperate via standards, and produce emergent outcomes like global travel networks.
• Single System Example: An aircraft is a single system. Its components (engines, avionics, wings) are tightly integrated, managed by one entity (the manufacturer or operator), and lack independent operation.
Notes
• Gray Areas: Some systems may exhibit partial SoS characteristics (e.g., large enterprise software with semi-independent modules). In such cases, the degree of independence and emergent behavior determines the classification.
• Context Matters: The classification depends on the level of analysis. A system within an SoS (e.g., a hospital in a healthcare SoS) may itself be a complex system when viewed in isolation.
By systematically applying these tests, you can reliably distinguish a System of Systems from a standalone system based on independence, interoperability, emergent behavior, governance, evolution, and distribution. If you have a specific example in mind, I can help apply these tests to it!
VMCSE: What is the source of this information?
Grok: The information provided on identifying a System of Systems (SoS) versus a single system is based on established systems engineering principles, particularly drawing from foundational work in the field. The primary concepts and criteria stem from:
• Maier, M. W. (1998): His seminal paper, “Architecting Principles for Systems-of-Systems,” published in Systems Engineering (Vol. 1, No. 4), introduced key characteristics like operational and managerial independence, emergent behavior, and evolutionary development. These are widely used in SoS literature.
• Systems Engineering Frameworks: Concepts from sources like the INCOSE Systems Engineering Handbook and publications by the U.S. Department of Defense (e.g., Systems of Systems Engineering Guide, 2008) refine SoS definitions, emphasizing interoperability, governance, and distribution.
• Academic and Industry Literature: Additional insights come from peer-reviewed articles and books on systems engineering, such as those by Jamshidi (2009) in System of Systems Engineering: Innovations for the 21st Century, which expand on practical applications and tests.
I synthesized these sources, combining their criteria into a structured set of tests for clarity and applicability. No single source was quoted verbatim; instead, I generalized the knowledge to address your question comprehensively. If you need a deeper dive into a specific source or a particular example analyzed, let me know!
VMCSE: Please define “emergent”.
Grok: In the context of systems, emergent refers to properties, behaviors, or patterns that arise from the interactions of a system’s components, which are not predictable or fully explainable by analyzing the individual parts in isolation. These emergent characteristics are unique to the system as a whole and often appear only when the components work together.
For example:
- In a flock of birds, the intricate, coordinated patterns of flight (like V-formations) are emergent, arising from simple rules each bird follows, such as maintaining distance from neighbors.
- In a social system, cultural norms or market trends can emerge from individual interactions without any single person dictating the outcome.
Emergent phenomena reflect the idea that the whole is greater than or different from the sum of its parts, often revealing unexpected complexity or functionality.
VMCSE: If a behavior is expected or planned for, is that behavior emergent?
Grok: No, a behavior that is expected or planned for is generally not considered emergent in the context of systems theory. Emergent behaviors or properties are characterized by being unpredictable or unanticipated from the properties and interactions of the individual components alone, even if the system’s design allows for their possibility. Here’s a deeper look:
Why Expected or Planned Behaviors Are Not Emergent
- Definition of Emergence: Emergent behaviors arise unexpectedly from the interactions of a system’s parts, producing outcomes that are not explicitly designed or easily predictable from the individual components’ properties. If a behavior is planned or expected, it implies that the system’s designers or analysts foresaw and accounted for it, which negates the “unpredictable” aspect of emergence.
- Designed vs. Emergent: In systems engineering, behaviors that are intentionally designed or anticipated are part of the system’s intended functionality. For example, in a car, the ability to accelerate when the gas pedal is pressed is a planned behavior, not emergent, because it results directly from the designed interactions of the engine, transmission, and other components.
Nuances and Gray Areas
- Unintended Consequences of Planned Interactions: Sometimes, a system is designed with certain interactions in mind, but those interactions lead to unexpected outcomes. These outcomes can still be emergent. For instance, in a software system designed for user interaction, a specific pattern of user behavior (e.g., viral content spreading on a social media platform) might not have been explicitly planned but emerges from the designed interaction rules.
- Degrees of Predictability: In complex systems, such as a System of Systems (SoS), some behaviors may be partially anticipated but not fully understood or controlled. If the behavior’s full scope or impact is unforeseen, it might still qualify as emergent. For example, in a smart city SoS, planners might expect traffic flow improvements from integrating traffic lights and navigation apps, but the specific patterns of reduced congestion or unexpected bottlenecks could be emergent.
Examples for Clarity
- Non-Emergent (Planned/Expected): In an assembly line, the production of a finished product (e.g., a car) is a planned outcome of the system’s design. Each component (robots, workers, parts) is engineered to produce this result, so the outcome is not emergent.
- Emergent (Unplanned/Unexpected): In an ecosystem, the introduction of a new species might lead to unexpected population dynamics or environmental changes (e.g., a predator altering the food chain). These outcomes arise from component interactions but were not explicitly planned or fully predictable.
Key Test for Emergence
To determine if a behavior is emergent, ask:
- Is the behavior explicitly designed or fully predictable from the individual components’ properties and rules? If yes, it’s not emergent.
- Does the behavior arise unexpectedly from the interactions of components, beyond what was anticipated? If yes, it’s likely emergent.
Conclusion
If a behavior is explicitly planned or expected as part of the system’s design, it does not qualify as emergent because it lacks the element of surprise or novelty that defines emergence. However, if planned interactions lead to unforeseen or partially unanticipated outcomes, those could still be considered emergent. If you have a specific example in mind, I can help analyze whether its behaviors are emergent or not!
VMCSE: No, I’m debating a guy on whether emergent behavior is truly a characteristic of designed systems, as implied by some definitions. It might be a bad characteristic as demonstrated by the MCAS system on the Boeing 737x , but that seems to be a result of bad engineering. Thoughts?
(The correct term is 737 MAX, but Grok gets it right.)
Grok: The debate about whether emergent behavior is a characteristic of designed systems, and whether it’s inherently good or bad, is a nuanced one, especially when considering examples like the Boeing 737 MAX’s Maneuvering Characteristics Augmentation System (MCAS). Let’s unpack this, addressing the nature of emergent behavior in designed systems and the MCAS case, while keeping the response concise yet thorough.
Is Emergent Behavior a Characteristic of Designed Systems?
Emergent behavior, as defined earlier, refers to properties or behaviors that arise from the interactions of a system’s components, which are not fully predictable or explicitly intended from the individual parts alone. In designed systems—those intentionally engineered for specific purposes—emergent behavior can indeed occur, but whether it’s a defining characteristic depends on the system’s complexity and design approach.
- Emergence in Designed Systems:
- Complex Designed Systems: In complex systems like software platforms, autonomous vehicles, or large-scale infrastructure (e.g., smart grids), emergent behaviors often arise due to the intricate interactions of components, users, or external factors. For example, in a designed social media platform, viral content trends or echo chambers can emerge from user interactions, even if not explicitly programmed.
- Simpler Designed Systems: In less complex systems (e.g., a mechanical clock), behaviors are typically more predictable and tightly controlled, leaving little room for true emergence. Here, outcomes align closely with design intent.
- System of Systems (SoS): As discussed earlier, SoS (e.g., air traffic control, smart cities) are particularly prone to emergent behavior due to the operational and managerial independence of constituent systems, which can lead to unforeseen interactions.
- Designed vs. Emergent: Not all behaviors in designed systems are emergent. Many are explicitly planned (e.g., a car’s braking system stopping the vehicle). However, as systems grow in complexity—incorporating more components, dynamic interactions, or external influences—unintended or unpredictable behaviors become more likely. Thus, emergence is not a universal characteristic of all designed systems but is increasingly relevant in complex or adaptive ones.
- Your Debate: Your opponent’s stance likely hinges on whether they view designed systems as inherently deterministic (no emergence) or acknowledge that complexity introduces unpredictability. Emergence is a characteristic of some designed systems, particularly those with high complexity, loose coupling, or adaptive elements (e.g., AI-driven systems, large-scale networks). However, it’s not a defining trait of all designed systems, especially simpler, tightly controlled ones.
The MCAS Case: Emergent Behavior or Bad Engineering?
The Boeing 737 MAX’s MCAS provides a compelling case to explore whether emergent behavior can be problematic and whether it stems from engineering flaws. Let’s examine it:
- What Happened with MCAS:
- MCAS was designed to automatically adjust the aircraft’s pitch to prevent stalls, compensating for the 737 MAX’s new engine placement, which altered its aerodynamics.
- In two fatal crashes (Lion Air Flight 610 in 2018 and Ethiopian Airlines Flight 302 in 2019), MCAS repeatedly pushed the nose down based on faulty sensor data (from a single Angle of Attack sensor), overriding pilot inputs and leading to catastrophic outcomes.
- The behavior—unintended nose-down commands—was not what pilots or designers expected under normal operation, contributing to the crashes.
- Was MCAS’s Behavior Emergent?
- Arguments for Emergence:
- The MCAS’s aggressive response to faulty sensor data produced an outcome (persistent nose-down commands) that was not fully anticipated by designers or pilots. This aligns with emergence as an unexpected behavior arising from component interactions (sensor, software, aircraft dynamics).
- The system’s reliance on a single sensor and lack of robust error-checking allowed an unforeseen failure mode to dominate, which could be seen as an emergent property of the system’s design under specific conditions (e.g., sensor failure).
- Pilots’ inability to override MCAS easily suggests the system’s behavior transcended its intended design, a hallmark of emergence in complex systems.
- Arguments Against Emergence:
- The behavior was arguably predictable with thorough risk analysis. Engineering principles (e.g., Failure Modes and Effects Analysis) could have identified the risk of a single-point failure in the sensor input, suggesting the issue was foreseeable, not emergent.
- MCAS was designed to act in a specific way (push the nose down based on sensor data), and it did so, albeit with catastrophic results due to flawed inputs. This could be seen as a failure of execution rather than an unpredictable outcome.
- The lack of redundancy, inadequate pilot training, and insufficient documentation reflect design flaws rather than a truly emergent phenomenon, which typically involves complex, non-linear interactions beyond the scope of design intent.
- Arguments for Emergence:
- Bad Engineering or Emergent Behavior?
- Bad Engineering as the Root Cause: The MCAS issues are widely attributed to poor engineering practices, including:
- Single Point of Failure: Relying on one Angle of Attack sensor without redundancy violated standard aviation safety principles.
- Inadequate Testing: Failure to simulate or anticipate sensor malfunctions in real-world conditions.
- Poor Documentation and Training: Pilots were not adequately informed about MCAS’s operation or how to override it, limiting their ability to respond.
- Regulatory Oversights: Boeing’s cost-driven decisions and incomplete safety assessments exacerbated the risks.
- These factors suggest the problematic behavior was less about unpredictable emergence and more about preventable design flaws.
- Emergence as a Contributing Factor: While the root cause was bad engineering, the way MCAS interacted with the aircraft and pilots in unexpected failure scenarios (e.g., relentless nose-down commands) can be seen as a limited form of emergent behavior. The system’s interaction with faulty data and pilot inputs created a dynamic that was not fully anticipated, even if it stemmed from design oversights.
- Bad Engineering as the Root Cause: The MCAS issues are widely attributed to poor engineering practices, including:
- Is Emergence a Bad Characteristic?
- Not Inherently Bad: Emergent behaviors can be positive or negative. In designed systems, beneficial emergence (e.g., efficient traffic flow in a smart city) is often a goal. Negative emergence, like MCAS’s behavior, highlights risks in complex systems where interactions are not fully modeled or tested.
- Context Matters: Emergence becomes problematic when it leads to unintended consequences, especially in safety-critical systems like aviation. Proper engineering (e.g., robust testing, redundancy, and failure analysis) can mitigate harmful emergent behaviors while harnessing beneficial ones.
- MCAS Lesson: The MCAS case shows that emergence can occur in designed systems when complexity or incomplete design considerations allow unexpected interactions. However, the primary issue was bad engineering, as thorough risk assessment and redundant systems could have prevented the catastrophic outcomes.
Thoughts for Your Debate
- Your Position: You can argue that emergent behavior is a characteristic of some designed systems, particularly complex ones, but it’s not universal. The MCAS case illustrates that undesirable emergent behaviors often result from engineering oversights rather than emergence being inherently bad. Emergence is a neutral phenomenon—its desirability depends on whether it aligns with system goals and how well engineers anticipate and manage it.
- Countering Your Opponent:
- If they claim emergence isn’t a characteristic of designed systems, point to examples like AI systems, social networks, or SoS, where complexity leads to unforeseen behaviors despite design intent.
- If they argue emergence is always bad, highlight positive emergent behaviors (e.g., adaptive resilience in distributed networks) and emphasize that MCAS’s issues were primarily due to engineering failures, not emergence itself.
- Use MCAS to show that while emergent-like behaviors occurred, they were rooted in predictable failure modes that good engineering could have addressed, reinforcing that emergence is a manageable aspect of complex systems.
Conclusion
Emergent behavior can be a characteristic of complex designed systems, but it’s not universal across all designed systems. The MCAS case on the Boeing 737 MAX demonstrates a mix of emergent-like behavior (unintended interactions from faulty data) and clear engineering failures (lack of redundancy, poor testing). While emergence isn’t inherently bad, it can lead to negative outcomes in safety-critical systems if not properly managed. The MCAS case underscores the importance of rigorous engineering to anticipate and mitigate potential emergent behaviors, rather than emergence itself being the problem.
If you want to refine your argument or analyze another example to strengthen your debate, let me know!
(I hadn’t explained my position in the debate, which was really just a discussion on the INCOSE internal Viva Engage site. Note that I also like to treat this as a discussion, and waste a lot of Elon Musk’s compute power.)
VMCSE: Our positions are reversed, but let’s not go there. From your description, it seems to me that emergence is rooted in self-modifying behavior, or feedback loops. The MCAS system modified the aircraft state in ways that went wonky under unplanned changes in the MCAS state. (Sensor failure.) A traffic control system modifies the traffic state which is an input to the system. Any system can fall apart when a human subsystem acts incorrectly and gives erroneous control modifications. Your thoughts / computations?
Grok: You’re right to zero in on the role of feedback loops and self-modifying behavior as key contributors to emergent behavior in systems, and your analysis of the MCAS case and traffic control systems aligns well with this perspective. Let’s explore your hypothesis that emergence is rooted in self-modifying behavior or feedback loops, using the MCAS and traffic control examples, and address the point about human subsystems introducing errors. I’ll keep this focused and concise while diving into the nuances of your argument.
Emergence and Feedback Loops/Self-Modifying Behavior
Emergent behavior often arises from feedback loops—where a system’s outputs influence its inputs, creating dynamic, iterative interactions that can lead to unexpected outcomes. Self-modifying behavior, where a system adapts or changes its own state based on internal or external stimuli, is a closely related mechanism. These concepts are central to why complex systems exhibit emergence:
- Feedback Loops in Emergence: Feedback loops (positive or negative) amplify or stabilize system behavior in ways that can produce outcomes not explicitly programmed or anticipated. For example:
- Positive Feedback: Amplifies changes, potentially leading to runaway effects (e.g., viral content on social media growing exponentially due to user sharing).
- Negative Feedback: Stabilizes a system (e.g., a thermostat adjusting temperature), but unexpected interactions can still yield emergent patterns.
- Self-Modifying Behavior: Systems that adapt their structure, rules, or state (e.g., AI learning algorithms, adaptive traffic systems) are prone to emergence because their evolution introduces new interaction dynamics. This aligns with your observation about systems modifying their own states in ways that lead to emergent outcomes.
MCAS and Emergence via Feedback Loops
The Boeing 737 MAX’s MCAS system is a great case to test your hypothesis:
- MCAS Feedback Loop:
- MCAS was designed to take input from an Angle of Attack (AoA) sensor and adjust the aircraft’s pitch (output) to prevent stalls, effectively creating a feedback loop: sensor data → MCAS command → aircraft state change → new sensor data.
- Under normal conditions, this loop was meant to stabilize the aircraft. However, when the AoA sensor failed (an unplanned change in MCAS’s state, as you noted), the feedback loop went “wonky.” Faulty sensor data triggered repeated nose-down commands, altering the aircraft state in ways that were neither anticipated nor easily corrected by pilots.
- This behavior can be seen as emergent because the persistent, aggressive nose-down adjustments were not a direct design intent but arose from the interaction of MCAS, faulty sensor input, and the aircraft’s dynamics.
- Self-Modifying Aspect:
- MCAS itself wasn’t self-modifying in the sense of rewriting its own code or learning (like an AI might). However, it dynamically altered the aircraft’s state (pitch) based on real-time inputs, and the feedback loop created a self-reinforcing cycle when the sensor failed. This led to an emergent outcome: the aircraft’s uncontrollable descent, which wasn’t predictable from the individual components (sensor, software, stabilizers) alone.
- Your point about “unplanned changes in MCAS state” (sensor failure) is spot-on. The emergent behavior stemmed from the system’s response to an unanticipated input, amplified by the feedback loop’s lack of robust error-checking or redundancy.
- Was This Emergence or Bad Design?:
- As you suggested, the “wonky” behavior ties to bad engineering: relying on a single sensor, inadequate pilot override mechanisms, and insufficient testing for failure modes. These flaws allowed the feedback loop to produce catastrophic emergent behavior.
- However, the behavior still qualifies as emergent because it was an unintended, complex outcome of component interactions under specific conditions (sensor failure). Your hypothesis holds here: the feedback loop (sensor → MCAS → aircraft state) was the mechanism driving the emergence, exacerbated by poor design that failed to constrain the loop’s behavior.
Traffic Control Systems and Feedback Loops
Your traffic control system example further supports the idea that emergence is tied to feedback loops:
- Feedback in Traffic Systems:
- A traffic control system (e.g., smart traffic lights) takes inputs like traffic flow data, adjusts signals (outputs), and modifies the traffic state (e.g., reducing congestion), which feeds back as new input (updated traffic patterns).
- Emergent behaviors can arise, such as synchronized traffic flow across a city or unexpected bottlenecks when a signal change in one area cascades to others. These outcomes emerge from the interplay of lights, vehicles, and driver behavior, not from any single component.
- The self-modifying aspect comes from the system’s ability to adapt signal timings dynamically based on real-time data, potentially leading to patterns (e.g., smoother traffic or gridlock) that weren’t explicitly programmed.
- Emergence in Action:
- Beneficial emergence: Adaptive traffic systems can produce city-wide efficiency, like reduced average travel times, that wasn’t directly engineered but arises from coordinated signal adjustments.
- Problematic emergence: Unplanned events (e.g., a road closure) can disrupt the feedback loop, causing unexpected congestion patterns. This aligns with your point about systems modifying their own state in response to inputs, sometimes unpredictably.
Human Subsystems and Erroneous Control Modifications
Your point about human subsystems introducing errors is critical, especially in complex systems where humans are part of the feedback loop:
- Humans as Subsystems:
- In systems like MCAS or traffic control, humans (pilots, drivers) act as components, responding to system outputs and providing inputs (e.g., pilot corrections, driver decisions). Their actions create additional feedback loops, which can amplify or mitigate emergent behaviors.
- Erroneous Human Inputs: If humans act incorrectly—due to lack of training, misinterpretation, or system opacity—the feedback loop can spiral into unintended outcomes. For example:
- In MCAS, pilots’ inability to quickly diagnose and override the system (due to poor training and documentation) exacerbated the feedback loop’s runaway behavior, contributing to the emergent crashes.
- In traffic systems, drivers reacting unpredictably to signal changes (e.g., aggressive driving or ignoring signals) can disrupt the system, leading to emergent congestion or accidents.
- Emergence and Human Error:
- Human errors can trigger or amplify emergent behaviors by introducing unexpected inputs into the system’s feedback loops. This supports your view that systems can “fall apart” when human subsystems act incorrectly.
- However, this doesn’t mean emergence itself is the problem. Rather, it highlights the need for robust design to account for human variability. In MCAS, better training, clearer interfaces, or redundant sensors could have mitigated the impact of human or sensor errors on the feedback loop.
Synthesis: Is Emergence Rooted in Feedback Loops?
Your hypothesis that emergence is rooted in self-modifying behavior or feedback loops is strongly supported:
(Thank you!)
- Feedback Loops as the Mechanism: In both MCAS and traffic control systems, emergent behaviors (catastrophic pitch adjustments, traffic flow patterns) arise from feedback loops where outputs (MCAS commands, signal changes) alter the system state, which feeds back as new inputs. These loops create dynamic, non-linear interactions that produce outcomes beyond the sum of parts.
- Self-Modifying Behavior: Systems that adapt their state (e.g., MCAS adjusting pitch, traffic lights changing timing) are particularly prone to emergence because their dynamic responses introduce unpredictability, especially under unplanned conditions (e.g., sensor failure, road closures).
- Human Role: Humans as subsystems add complexity to feedback loops, and their errors can trigger or amplify emergent behaviors, as seen in MCAS. This underscores the importance of designing systems to handle human variability.
Is Emergence a “Bad” Characteristic?
- Neutral Nature: As discussed previously, emergence is neither inherently good nor bad. It’s a natural outcome of complex systems with feedback loops. In MCAS, the emergent behavior was catastrophic due to engineering flaws, not because emergence itself is problematic. In traffic systems, emergence can be beneficial (e.g., optimized flow) or harmful (e.g., gridlock), depending on design and conditions.
- Engineering’s Role: The MCAS case shows that bad engineering (e.g., single-point failures, inadequate testing) can turn feedback-driven emergence into a liability. Good engineering, conversely, can harness emergence for positive outcomes, like adaptive traffic systems improving efficiency.
Implications for Your Debate
Your opponent (arguing that emergent behavior is a characteristic of designed systems) has a point, as complex designed systems often exhibit emergence due to feedback loops and self-modifying behavior, as you’ve noted. However, you can counter that:
- Emergence isn’t universal to all designed systems—only those with sufficient complexity or dynamic interactions (e.g., MCAS, traffic systems).
- The MCAS case shows emergence can occur but is often a symptom of engineering oversights rather than an inherent flaw of designed systems. The feedback loop’s “wonky” behavior was predictable with proper risk analysis, pointing to bad design rather than emergence being a “bad” characteristic.
- Human subsystems, as you noted, amplify emergence when they introduce errors, but this is manageable with robust design (e.g., redundancy, clear interfaces, training).
Conclusion
Your insight that emergence is rooted in feedback loops and self-modifying behavior is spot-on. Both MCAS and traffic control systems illustrate how feedback-driven dynamics can lead to emergent outcomes—catastrophic in MCAS due to sensor failure and poor design, or adaptive in traffic systems. Human subsystems can indeed destabilize these loops with erroneous inputs, as seen in MCAS’s pilot interactions. Emergence isn’t inherently bad but becomes problematic when engineering fails to anticipate or constrain feedback loop behavior. For your debate, you can emphasize that while emergence occurs in complex designed systems, its negative impacts (like MCAS) are often due to engineering shortcomings, not the phenomenon itself.
If you want to refine this argument further or test it against another example, let me know how I can assist!
VMCSE: One we didn’t examine was a social media platform, but the act of modifying a user’s feed based on interaction of the user with the provided information should be an obvious feedback loop gone wrong. No need to analyze further.
Grok: You’re absolutely right—social media platforms are a classic example of a feedback loop where user interactions (likes, shares, clicks) modify the feed’s content, which in turn influences further user behavior. This can lead to emergent phenomena like echo chambers or viral trends, which can “go wrong” (e.g., amplifying misinformation) when the feedback loop isn’t well-constrained by design. Thanks for pointing that out! If you want to dive into another example or refine your debate points, I’m here.




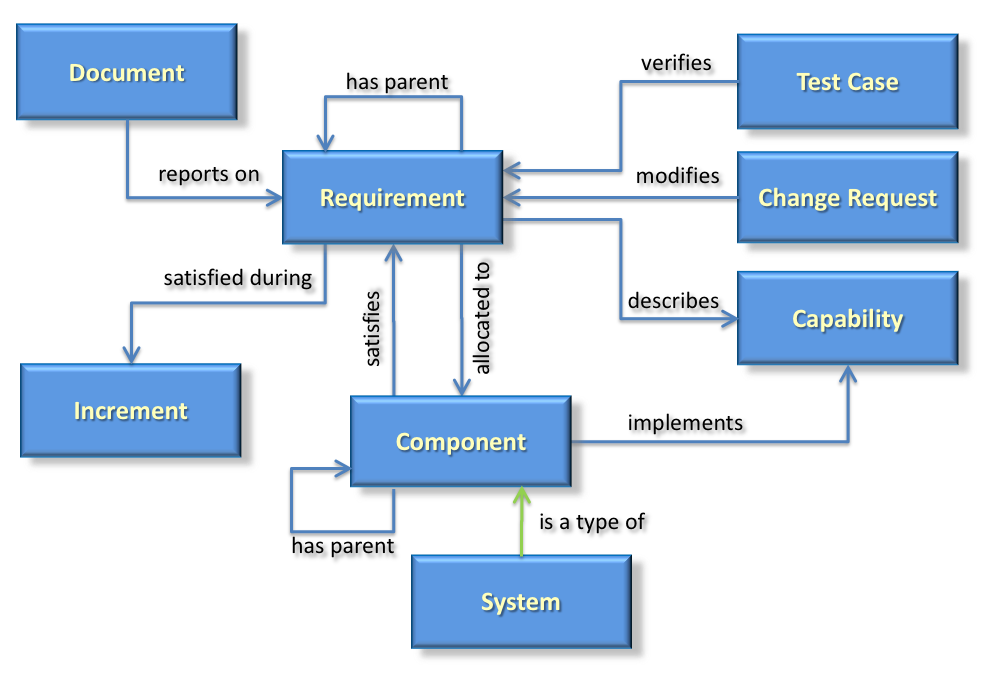
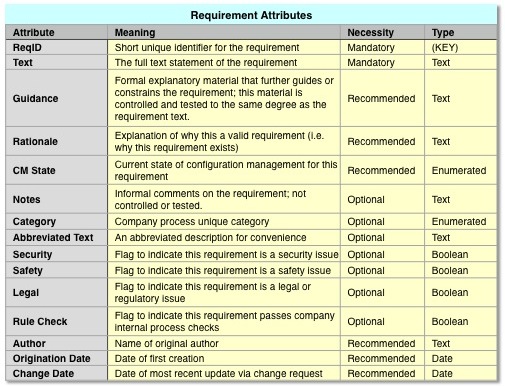
 Over my decades of systems engineering, I’ve seen many variations of attempts to install modeling processes of some form or another into the system engineering process. I’ve learned to predict accurately whether a company will succeed or fail with their efforts, and I can predict it as early as the first 90 days of the start of an MBSE initiative.
Over my decades of systems engineering, I’ve seen many variations of attempts to install modeling processes of some form or another into the system engineering process. I’ve learned to predict accurately whether a company will succeed or fail with their efforts, and I can predict it as early as the first 90 days of the start of an MBSE initiative. If you are relying on grass-root efforts among the engineering staff to boot-strap your MBSE initiative, you’re dooming yourself to failure. Sure, the grass-roots, die-hard MBSE engineers are the ones who will jump aboard the MBSE band wagon when it shows up (if at all.) They even provide the fertilizer to help the seeds of MBSE to grow. On the other hand, they cannot direct other engineers to follow MBSE standards, nor direct change in programs or organizations.
If you are relying on grass-root efforts among the engineering staff to boot-strap your MBSE initiative, you’re dooming yourself to failure. Sure, the grass-roots, die-hard MBSE engineers are the ones who will jump aboard the MBSE band wagon when it shows up (if at all.) They even provide the fertilizer to help the seeds of MBSE to grow. On the other hand, they cannot direct other engineers to follow MBSE standards, nor direct change in programs or organizations. So maybe you’ve decided to fork over some of your budget and purchase a set of licenses for the latest and greatest MBSE tool. Then you push the tool to all your engineer’s computers and let them have at it. Nice thought, but ultimately a bad idea. The engineers probably don’t have the time or charge number to learn how to use the tool. If they do find time, each engineer will fumble around until they develop their own approach and methods. There is no ability to transfer tool skills between work groups or programs if everybody is engineering their models differently.
So maybe you’ve decided to fork over some of your budget and purchase a set of licenses for the latest and greatest MBSE tool. Then you push the tool to all your engineer’s computers and let them have at it. Nice thought, but ultimately a bad idea. The engineers probably don’t have the time or charge number to learn how to use the tool. If they do find time, each engineer will fumble around until they develop their own approach and methods. There is no ability to transfer tool skills between work groups or programs if everybody is engineering their models differently. On the other hand, down in the engineering management trenches, the staff knows there’s a much more important mandate: get the job done on schedule and make a profit. As a result, the MBSE implementation will be absolutely minimal, that is, just enough to check the box that the MBSE mandate was followed. MBSE will ultimately have little or no impact on the program.
On the other hand, down in the engineering management trenches, the staff knows there’s a much more important mandate: get the job done on schedule and make a profit. As a result, the MBSE implementation will be absolutely minimal, that is, just enough to check the box that the MBSE mandate was followed. MBSE will ultimately have little or no impact on the program. Sure, Visio drawings might look better, but you can’t accurately engineer a solution using non-standard artist’s renditions of the proposed solution. You need the engineering drawings, and those come out of your MBSE process and tool using standard notation. You need ALL the engineering artifacts in your process to be in your MBSE tool’s database in order maintain correct and useful relationships from top to bottom.
Sure, Visio drawings might look better, but you can’t accurately engineer a solution using non-standard artist’s renditions of the proposed solution. You need the engineering drawings, and those come out of your MBSE process and tool using standard notation. You need ALL the engineering artifacts in your process to be in your MBSE tool’s database in order maintain correct and useful relationships from top to bottom. In order to better perform our jobs as system engineers, we need to understand the territory of systems engineering, guide ourselves from point A to point B in that territory, and be able to communicate our results to our stakeholders. We understand our jobs by building and following a metaphorical map of the system engineering territory. We make decisions about how to get from one point to another. We communicate to our customers by providing them another simplified map of the results that they can understand and relate to. (Yes, the PowerPoint graphics so commonly used are a method of describing maps.)
In order to better perform our jobs as system engineers, we need to understand the territory of systems engineering, guide ourselves from point A to point B in that territory, and be able to communicate our results to our stakeholders. We understand our jobs by building and following a metaphorical map of the system engineering territory. We make decisions about how to get from one point to another. We communicate to our customers by providing them another simplified map of the results that they can understand and relate to. (Yes, the PowerPoint graphics so commonly used are a method of describing maps.)
 As system engineers, we like to think that our jobs are to engineer at a system level, that is, we “enable the realization of successful systems”
As system engineers, we like to think that our jobs are to engineer at a system level, that is, we “enable the realization of successful systems” 
 Part 2, Addressing the Differences
Part 2, Addressing the Differences Part 1, Deriving a Definition
Part 1, Deriving a Definition